果然用浏览器访问才是王道...
# 前情提要
之前自己帮朋友搞一个爬虫小项目。需求说是很简单:用excel批量导入链接,每天定时访问这些链接,然后爬取该页面的相关信息,再存入excel,可以导出。
最开始搞的时候,确实还挺简单,拿着几个链接在本地测试很快就搞好了,然而一放上我的小水管vps就不行了,实际使用的时候是批量爬几百几千个网址。而且爬的是国内某知名网站,肯定是对于爬虫有防御机制,爬着爬着就给我返回一堆不知所云的文字了,也就是该网站把我的vps拉入ip限制黑名单了。
为了解决问题我试了好多种方法
每个网址间隔几秒到十几秒访问, 同链接的爬取结果缓存一段时间。(ip还是会被封,无效)
用无数个代理ip访问,这个是很多爬虫的方法。大多数有效的代理ip要花钱,价格不菲。为了获取免费的代理ip,我又去爬一个免费代理ip的网址来获取代理ip,甚至搞了个项目。搞的很复杂然而免费的代理ip很快就会过期,还有延时长的问题,爬取效率也很低。
2方法虽然略慢 但是还是解决了问题一阵子。然而尴尬的事情出现了,我爬的免费代理的网页,也把我墙了。。另外还有个问题,这爬虫一直挂在我的小水管服务器上定时爬,占了我服务器的流量,我还得保证它的运行,很不划算。
最后突然想到,网站一般通过区分浏览器访问和机器访问来反爬,如果我就是用浏览器访问的呢?所以想到了electron,并且这东西可以编译成windows、mac软件直接安装在电脑本地,再也不用在我的小水管上爬了,简直完美。
# 大概思路
- 初始化项目
npm install -g vue-cli
vue init simulatedgreg/electron-vue electron-spider
# Install dependencies and run your app
cd electron-spider
yarn # or npm install
yarn run dev # or npm run dev
2
3
4
5
6
7
- 主要页面
由于是例子,直接改生成项目里的landingPage.vue页面了,我们爬一下掘金,直接上代码吧
大致思路,用webview打开需要爬取的网址,该webview preload一个js文件,该文件可以访问新页面并且进行dom读取等操作(类似在浏览器控制台里执行js)。通过electron的相关进程直接通信的api和事件,进行数据传输,主页面拿到数据后可以存储起来或者做别的事。
<template>
<div id="wrapper">
<button
@click="doSearch"
:disabled="isSearching">开始爬取</button>
<p v-if="isSearching">
爬取中, url: {{url}}
</p>
<!-- 爬取网址的webview, 该页面 -->
<webview class="search-webview" id="webview" src="" autosize="on" minwidth="1" minheight="1" :preload="fileName"></webview>
文章列表
<ul>
<li v-for="post in posts" :key="post.link">
<a :href="post.link" target="_blank">{{ post.title }}</a>
</li>
</ul>
</div>
</template>
<script>
import path from 'path'
export default {
name: 'landing-page',
data () {
return {
isSearching: false,
url: 'https://juejin.im',
posts: [],
webview: null,
// preload的文件地址
fileName: `file://${path.join(__static, '/doSearch.js')}`
}
},
mounted () {
this.webview = document.getElementById('webview')
this.webview.addEventListener('ipc-message', this.receiveMessage)
},
methods: {
receiveMessage (e) {
const result = JSON.parse(e.args[0])
this.posts = result || []
this.isSearching = false
},
searchHanlder () {
this.webview.send('ping', 'xxxx')
},
/** 开始爬取 */
doSearch () {
const { url, isSearching } = this
if (isSearching) return
const webview = this.webview
webview.src = url
this.isSearching = true
this.searchUrl = url
webview.addEventListener('dom-ready', this.searchHanlder)
}
}
}
</script>
<style>
.search-webview{
display: block;
visibility: hidden;
height: 0;
}
</style>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
- doSearch.js
const ipcRenderer = require('electron').ipcRenderer
function getPostList () {
const postElems = document.querySelectorAll('.entry-list>li.item')
const list = []
postElems.forEach(item => {
const linkElem = item.querySelector('.title-row a') || {}
list.push({
---
title: linkElem.innerText || '',
link: linkElem.href || ''
})
})
return list
}
function main () {
// 延迟时间等dom渲染
setTimeout(() => {
const list = getPostList()
ipcRenderer.sendToHost('data', JSON.stringify(list))
}, 100)
}
main()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
效果:
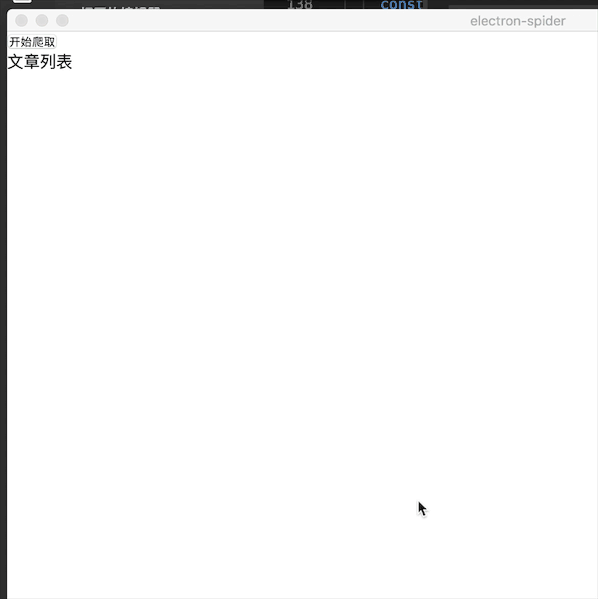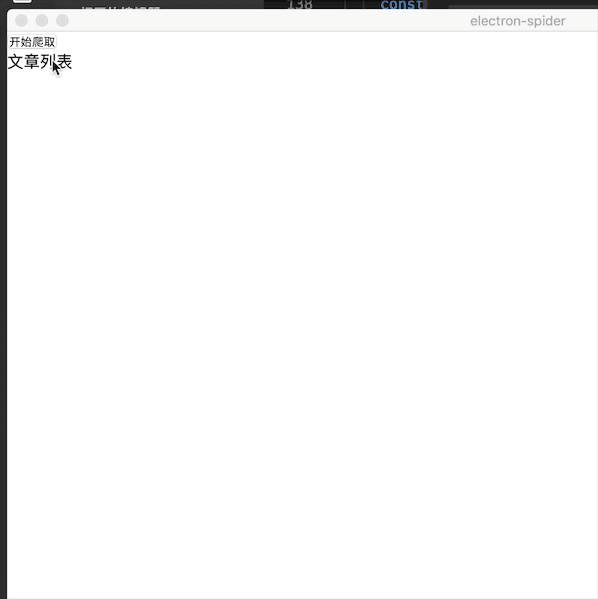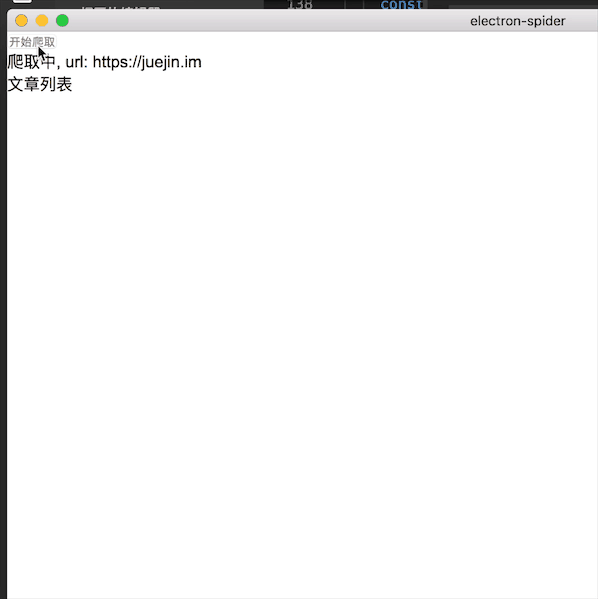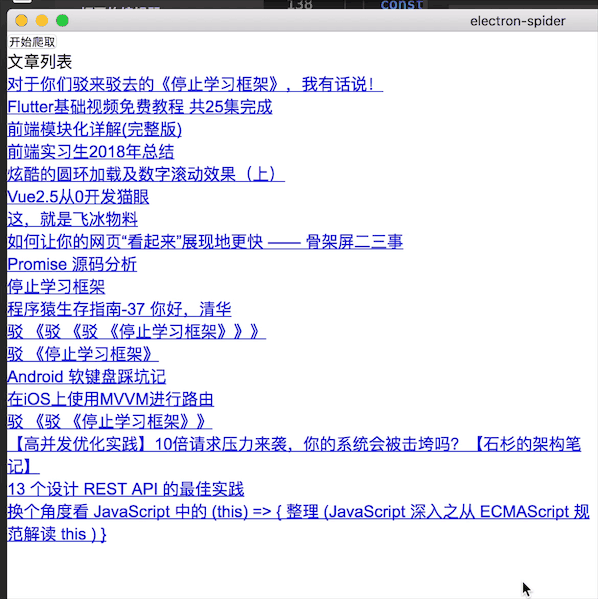
全部代码在https://github.com/cky917/electron-spider
利用electron能做好多事,比如定时操作、本地存储等等。
# 后话
这个“小项目”当时真是折磨了我好久,也了解了好多反爬的知识,网站反爬策略越来越丰富,除了ip频率控制、浏览器注入cookie判断、甚至有网站会判断鼠标移动之类的用户操作来判断你是不是机器人,当然还有最有效的验证码机制。爬虫和反爬之间的斗智斗勇,感觉就是技术的博弈。爬虫其实对网站还是有影响的,最好要控制频率,不要恶意进行爬取,不然你还是可能会被封ip。